Au fil de plusieurs articles, je vais publier quelques exemples de masterspins que j’ai qualifié.
Les analyses publiées sont anonymes, et sont basées sur des cas « typiques ».
L’objectif de ces articles est de vous montrer ce qu’on peut déduire, calculer à partir d’un masterspin, mais aussi de vous fournir un guide pour interpréter les analyses de vos propres MasterSpins.
Le masterspin étudié ici est un projet xSpin. C’est un bon masterspin, dans la moyenne.
Episode 1 : Analyse du masterspin du point de vue quantitatif
On s’attache ici à l’aspect Sorties possibles, similitude. C’est l’indicateur principal que chacun veut obtenir.
Le masterspin pèse 8Mo. Son graphe compte plus d’un millions de noeuds, pour 477 noeuds uniques et 200000 noeuds vides.
300000 perforations, 400000 alternatives.
La méthodologie:
De ce masterspin, converti sous forme de graphe, j’ai effectué 30000 tirages optimisés (tirages qui sortent en priorité les chemins les moins utilisés, donc à priori des sorties plus uniques que par un tirage purement aléatoire.)
Pour chacun de ces 30000 tirages, j’ai calculé la distance entre ce tirage et les 29999 autres (soit 450 millions de comparaisons). Ma mesure de distance est un algorithme personnel que je garde secret.
Elle est calculée à partir d’un texte normalisé, après suppression de stop words, et prend en compte tant les mots du texte que leur ordre. Son objectif est de coller au mieux à ce que je suppose et infère du fonctionnement de Google.
Une fois que j’ai cette matrice de distances, je peux passer à l’étape suivante : le filtrage.
Je me fixe une similitude maximum, « S », et j’enlève du pool d’articles tous ceux qui sont à plus de S similaires à un autre.
Il ne me reste que N articles qui sont les plus éloignés possibles les uns des autres, au plus à S% de similitude.
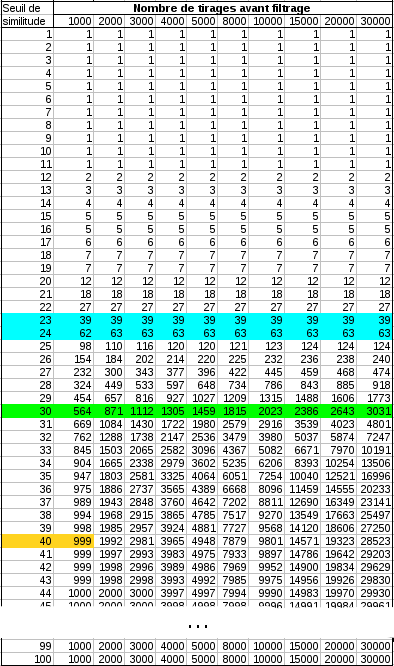 Dans le tableau ci-contre, j’ai représenté pour une similitude qui varie de 1 à 100, combien d’articles il me reste après filtrage.
Dans le tableau ci-contre, j’ai représenté pour une similitude qui varie de 1 à 100, combien d’articles il me reste après filtrage.
Chaque colone représente un nombre de tirages différent.
Ainsi, colonne 1, on peut voir ce qui se passe si on avait travaillé sur 1000 tirages au lieu de 30000 (C’est bien plus rapide, et suffisant dans bien des cas).
Ce qu’on voit dans ce tableau:
Si on se fixe un seuil de similitude faible (<11%), que l'on tire 1000 ou 30000 articles (ou plus), on n'a toujours qu'un seul article après filtrage. A 15 % de similitude, on a 5 articles suffisamment différents, pas plus (se produit jusque la ligne bleue)
A l'opposé, si on se fixe un seuil élevé, au dessus de 50% de similitude, on remarque qu'on ne perd aucun article.
en tirant 20000 articles (attention, le tirage n'est pas aléatoire, il sort les à priori plus différents en premier)
on n'a encore aucun article qui soit proche à plus de 50% des autres. Si on a un seuil élevé, on peut utiliser ce masterspin presque sans limite.
Ce qui est intéressant et qui caractérise le masterspin se trouve entre les deux, vers les 30% de similitude.
C'est autour de cette valeur que tout se passe. (Voir également le graphique 1 ci-dessous)
Les réponses apportées par ce tableau sont les suivantes :
- je me fixe un seuil (arbitraire, celui là marche bien pour moi) de 30% de similitude maxi. Combien de tirages puis-je faire ?
réponse (ligne verte) : plus de 500 si je filtre à partir de 1000, 3000 si je pousse à 30000 tirages.
On remarque au passage que plus on tire d’articles, et moins on en trouve de différents.
Entre 1000 et 2000, j’ai tiré 1000 articles de plus, j’en ai gagné 307 (30% des tirages en plus).
Entre 20000 et 30000, j’ai tiré 10000 articles de plus, j’en ai gagné 388 seulement (3.8%).
Si on continue à effectuer des tirages, on en aura quelques uns en plus, mais on aura du mal à arriver à 10000… - Je veux exprimer au mieux la diversité de mon masterspin, avec la meilleure qualité possible.
On regarde à partir de quelle similitude les courbes « décollent » (lignes bleues).
On est dans les 23, 24%, avec une cinquantaine de tirages différents.
Pour cela, on voit qu’il est inutile de tirer 30000 articles : avec 1000, on a déjà atteint la diversité maximale, on n’aura pas plus. - Je veux 500 articles, les plus éloignés.
on peut partir de 1000 tirages filtrés, on aura entre 29 et 30% de similitude maxi.
Ou partir de 30000 tirages, et on aura alors environ 27% de similitude. - Je ne filtre pas, je vais juste faire 1000 tirages aléatoires, quelle sera ma similitude maxi ?
Case orange, ça sera 40% (ou un peu plus à cause du tirage aléatoire)
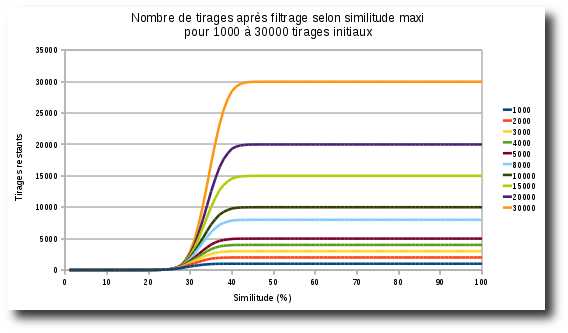
Graphique 1: illustration graphique du tableau 1
Le graphique suivant est peut être plus parlant pour montrer ce qui se passe, et le phénomène de saturation au fil des tirages.
Les données du tableau 1 sont converties en pourcentages, et l’on voit le % de déchets par rapport au seuil de similitude.
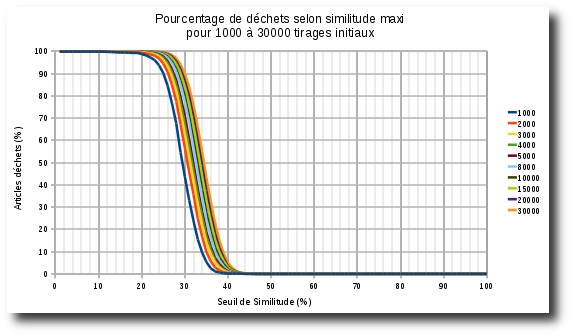
Graphique 2
Pour des similitudes faibles, déchet de 99.9% (un seul article!)
Pour des similitudes élevées, 0% de déchet (tous les articles suffisamment uniques)
Entre les deux, on voit la saturation: plus on augmente le nombre de tirages, et moins la courbe « avance ».
entre 1000 et 2000, on voit nettement la progression. plus on avance, moins c’est net: la courbe tend vers une limite.
Tweeter !
Partager sur Facebook
Plus sur Google+
Epingler sur Pinterest
Dans l’épisode 2, L’analyse qualitative avec une visualisation graphique de l’ensemble du masterspin.
Pour la petite histoire, ce masterspin a été crée par un utilisateur quelques jours seulement après son abonnement au service xSpin. Premier projet, premier spin suffisamment bon pour être utilisé sans souci : bravo !